An old saying claims a healthy mind needs a healthy body. But, in turn, a healthy mind and a healthy body both need a healthy environment to develop in. Thus, protecting our environment has been a central part of Avallain’s DNA ever since the company was founded in 2002. We offer our customers carbon-neutral e-learning solutions which not only train minds but also minimise the CO2 emissions of entire learning courses as well.
In addition to providing sustainable education for people in need via the charitable Avallain Foundation, established in 2016, we will also commit ourselves more actively to projects focused entirely on environmental protection in the future. For example, we are currently helping specialists of the People for Cause foundation with their ReTree Initiative, planting a new forest area in the barren steppes of Spain.
Avallain supports the Spanish forests
The project in Spain ties into an almost 10-year-old Avallain tradition. In 2008, we helped the NGO Trees for the Future to plant 25’000 trees in Keroka, Kenya, celebrating the 250’000th learner that was educated using e-learning systems developed with our technology (today, they number in the millions).
In celebration of our 15-year anniversary, we want to set another example. Reforestation projects are vital in this part of southern Europe. While the ancient Greek geographer Strabon once wrote that a squirrel could “hop through the trees from the Pyrenees to Gibraltar without touching the ground”, deforestation has turned much of the country into steppes largely dominated by soil degradation. The Iberian Peninsula of today is suffering from frequent droughts and forest fires. In many areas, the ground is no longer protected against erosion by strong roots, and the once-fertile soil is gradually turning to dust or karst. For us humans, this means a steady decrease in agricultural usability – for Strabon’s squirrel and the Spanish wildlife, it might mean extinction.
With this new Avallain initiative, we are working to counteract this process. Of course, we also realise that small individual forested areas are not a viable long-term solution to the problem. Thus, we are planning to extend our efforts to other countries very soon as well.
Our success in this task is also the success of our customers, whose trust in our work allows us to engage in such projects in the first place.
Avallain works sustainably every step of the way
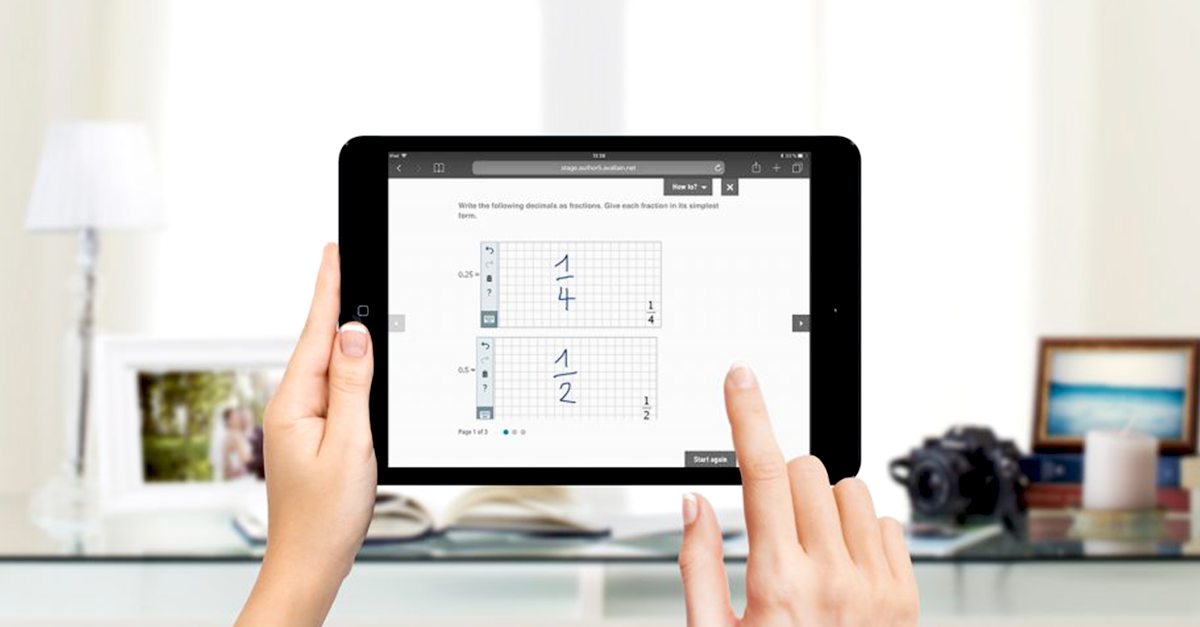
Our customers appreciate our innovative spirit, our reliability and our experience – as manifested both in our products Avallain Author and Avallain Unity, as well as in the e-learning systems created with them. Such systems are fully sustainable, protecting the environment at all stages, from the initial design process to maintenance and most importantly, the active use by learners.
Digital education is more environmentally friendly by its very nature
It may sound counter-intuitive, but e-learning constitutes a more environmentally sustainable alternative to analogue learning models such as brick and mortar learning groups. Though the digital infrastructure needed for e-learning tools does require energy – as well as digital devices which need to be produced and will be turned to waste eventually – neither the energy usage nor the CO2 emissions generated by e-learning approaches are even close to those of analogue learning methods.
According to a 2008 Open University study which focused on 13 fixed-location university courses and 7 online courses, e-learning courses require 87 % less energy than analogue courses, while emitting 85 % less CO2. The tangible benefits of e-learning are known throughout the industry:
- It eliminates carbon emissions created by each learner’s commute.
- It does not require heated and powered course premises or individual workstations.
- It minimises the use of printer cartridges and paper.
- It eliminates the need for non-recyclable utensils such as marker pens.
Thus, our customers can minimise the environmental impact of each learner enrolled in a course. Eliminating the CO2 emissions from commuting alone is enough to make many e-learning courses almost entirely carbon-neutral.
Sustainability in Avallain’s operating procedures
Of course, these principles work not only to minimise the CO2 emissions of individual learners – but they can also be applied to the working environment. As a staunch advocate of Remote Company structures, Avallain has been following this strategy for years, offering a large degree of home office flexibility to our workforce. Thus, we can avoid long daily commutes, minimising our CO2 footprint in the process. A Carbon Trust analysis suggests that, given average commuting distances, this saves approximately 260 kg of CO2 equivalent per worker each year.
Green business experts note that these carbon savings already apply to commuters travelling more than 7 km by car, 11 km by bus or 25 km by train. To an international company like us, this only serves to support our approach. Being a Remote Company allows us to offer our customers software solutions developed by a tight network of international specialists – without incurring the costs in CO2 which this might otherwise entail.
Limiting CO2 emissions with sophisticated technology
Not just our operating procedures are chosen on the basis of environmental questions – our technologies are, as well. Server systems, in particular, can have an enormous impact on the environment.
We recognised the potential of Cloud-based server structures early on, consequently taking on the responsibility to push for sustainable server use strategies with professional Cloud server providers. Today, providers such as Amazon Web Services are continually improving their technological solutions to operate their Cloud-servers as energy-efficient and as close to carbon-neutral as possible, devising strategies such as:
- Using renewable energy as a power source
- Employing energy-efficient cooling systems
- Optimising energy usage according to workload
Put together, such strategies allow Cloud systems to significantly reduce the number of servers used when compared to on-site servers. This also minimises the energy usage of Cloud systems by as much as 84 % compared to on-site servers. Thanks to our good business connections to Amazon, we are able to use CO2-neutral Cloud systems for 80 % of all Avallain services thus far – without increasing the price for our customers, as we compensate the additional costs.
The education of the future is carbon-neutral
What does all of this mean to the users of learning software based on Avallain Author and Avallain Unity? It means that they can not only improve their individual learning success thanks to innovative, technologically mature and reliable software – they can also do so while supporting a sustainable and future-proof approach to treating the environment.
Because this is what ultimately connects Avallain solutions with our Spanish forest: They both provide the roots on which future generations may tread.